
简介
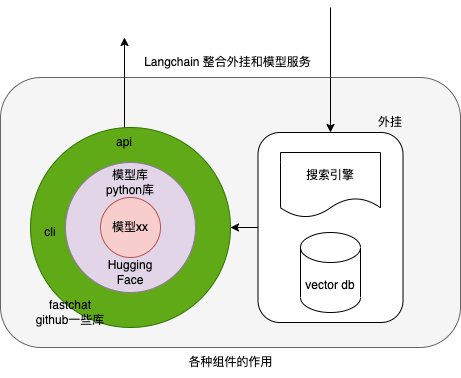
Hugging Face
Hugging Face 自然语言处理(NLP)的开源平台和社区,主要提供了以下几个产品和服务:
- Hub:这是一个机器学习的中心,让你可以创建、发现和协作ML项目。可以从排行榜开始,了解社区中表现较好的模型。如果你没有 GPU,你必须使用小的模型。转到文件目录并查看 .bin 文件的大小。有的项目在型号卡中也会提到所需的最低规格。PS:就像github 包含代码文件一样,这里包含代码的模型文件,git clone 时要安装Git LFS(Git Large File Storage)
- Transformers:这是一个自然语言处理的库,支持多种编程语言(如Python、JavaScript、Swift等)和框架(如PyTorch、TensorFlow等),并提供了简单易用的API,让你可以快速地加载、训练和部署模型。帮我们跟踪流行的新模型,并且提供统一的代码风格来使用BERT、XLNet和GPT等等各种不同的模型。只有configuration,models和tokenizer三个主要类,基于上面的三个类,提供更上层的pipeline和Trainer/TFTrainer,从而用更少的代码实现模型的预测和微调。
- pipeline 在底层是由 AutoModel 和 AutoTokenizer 类来实现的。AutoClass(即像 AutoModel 和 AutoTokenizer 这样的通用类)是加载模型的快捷方式,它可以从其名称或路径中自动检索预训练模型。
- ```python from transformers import MODEL_NAME # 导入模型 model = MODEL_NAME.from_pretrained(‘MODEL_NAME’) # 实例化模型,其中 MODEL_NAME 是模型的名称或路径。 inputs = xx # 准备输入数据,转换为模型支持的格式。(如 tokenizer 后的文本、图像等) outputs = model(inputs) # 调用模型并获得输出
model.save_pretrained(‘PATH’) # 将模型保存到指定路径 ```
- 在Linux下,模型默认会缓存到
~/.cache/huggingface/transformers/。所有的模型都可以通过统一的from_pretrained()函数来实现加载,transformers会处理下载、缓存和其它所有加载模型相关的细节。而所有这些模型都统一在Hugging Face Models管理。 - 最初我认为您需要为每个模型系列使用特定的Transformers和Tokenizer(例如,如果您使用T5模型系列,则对应T5Tokenizer和 T5ForConditionalGeneration),对于所有预训练模型,您可以声明一个简单的语句:
from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-3b") model = AutoModelForCausalLM.from_pretrained("databricks/dolly-v2-3b")
- Inference API:这是一个服务,让你可以直接从Hugging Face的基础设施上运行大规模的NLP模型,并在毫秒级别得到响应。
- Datasets:这是一个数据集的库,让你可以获取、加载和处理超过1400个公开可用的数据集。Datasets支持多种数据类型(如文本、图像、音频等)和格式(如JSON、CSV等),并提供了高效且统一的API,让你可以快速地加载、缓存和转换数据。
LangChain使用 Hugging Face 模型
- 使用在线模型
import os from langchain import PromptTemplate, HuggingFaceHub, LLMChain os.environ['HUGGINGFACEHUB_API_TOKEN'] = 'xx' template = """Question: {question} Answer: Let's think step by step.""" prompt = PromptTemplate(template=template, input_variables=["question"]) llm = HuggingFaceHub(repo_id="google/flan-t5-xl", model_kwargs={"temperature":0, "max_length":64}) llm_chain = LLMChain(prompt=prompt, llm=llm) question = "What NFL team won the Super Bowl in the year Justin Beiber was born?" print(llm_chain.run(question)) - 将 Hugging Face 模型直接拉到本地使用(有些模型无法在 Hugging Face 运行)
from langchain import PromptTemplate, LLMChain from langchain.llms import HuggingFacePipeline from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLM model_id = 'google/flan-t5-large' tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForSeq2SeqLM.from_pretrained(model_id) pipe = pipeline("text2text-generation",model=model,tokenizer=tokenizer, max_length=100) local_llm = HuggingFacePipeline(pipeline=pipe) print(local_llm('What is the capital of France? ')) template = """Question: {question} Answer: Let's think step by step.""" prompt = PromptTemplate(template=template, input_variables=["question"]) llm_chain = LLMChain(prompt=prompt, llm=local_llm) question = "What is the capital of England?" print(llm_chain.run(question))
模型服务
简单封装
ChatGLM-6B 在github 有一个仓库,一般包含
- 模型介绍 README.md
- 模型的对外接口 api.py/cli_demo.py/web_demo.py
以api.py 为例
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
app = FastAPI()
@app.post("/")
async def create_item(request: Request):
global model, tokenizer
json_post_raw = await request.json()
json_post = json.dumps(json_post_raw)
json_post_list = json.loads(json_post)
prompt = json_post_list.get('prompt')
history = json_post_list.get('history')
max_length = json_post_list.get('max_length')
top_p = json_post_list.get('top_p')
temperature = json_post_list.get('temperature')
response, history = model.chat(tokenizer,prompt, history=history,
max_length=max_length if max_length else 2048,
top_p=top_p if top_p else 0.7,
temperature=temperature if temperature else 0.95)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {"response": response,"history": history,"status": 200,"time": time}
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log)
torch_gc()
return answer
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
FastChat
FastChat是一个用于训练、服务和评估基于聊天机器人的大型语言模型的开放平台。核心功能包括:
- 最先进模型(如Vicuna、FastChat-T5)的权重、训练代码和评估代码。
- 一个具有web界面和openai兼容的RESTful api的分布式多模型服务系统。
LangChain
LangChain is a framework for developing applications powered by language models. We believe that the most powerful and differentiated applications will not only call out to a language model, but will also be:
- Data-aware: connect a language model to other sources of data
- Agentic: allow a language model to interact with its environment
如果是一个简单的应用,比如写诗机器人,或者有 token 数量限制的总结器,开发者完全可以只依赖 Prompt。当一个应用稍微复杂点,单纯依赖 Prompting 已经不够了,这时候需要将 LLM 与其他信息源或者 LLM 给连接起来(PS:重点不是模型服务本身),比如调用搜索 API 或者是外部的数据库等。LangChain 的主要价值在于:
- 组件:用于处理语言模型的抽象,以及每个抽象的一系列实现。无论您是否使用 LangChain 框架的其他部分,组件都是模块化且易于使用的。PS: 既可以单独用,也可以组合用。
- 现成的链式组装:用于完成特定高级任务的结构化组件组装。一些例子包括:
- 将 LLM 与提示模板结合。
- 通过将第一个 LLM 的输出作为第二个 LLM 的输入,按顺序组合多个 LLM。
- 将 LLM 与外部数据结合,例如用于问答系统。
- 将 LLM 与长期记忆结合,例如用于聊天历史记录。
基础功能
- Model,主要涵盖大语言模型(LLM)。支持流模式(就是一个字一个字的返回,类似打字效果)。
- Prompt,支持各种自定义模板
- 拥有大量的文档加载器,从指定源进行加载数据的,比如 Email、Markdown、PDF、Youtube …当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
- 对索引的支持
- 文档分割器,为什么需要分割文本?因为我们每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 openai api embedding 功能都是有字符限制的。比如我们将一份300页的 pdf 发给 openai api,让它进行总结,它肯定会报超过最大 Token 错。所以这里就需要使用文本分割器去分割我们 loader 进来的 Document。
- 向量化,数据相关性搜索其实是向量运算。以,不管我们是使用 openai api embedding 功能还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。
- 对接向量存储与搜索,比如 Chroma、Pinecone、Qdrand
- Chains
- LLMChain
- 各种工具Chain
- LangChainHub
Model,主要涵盖大语言模型(LLM)
from langchain.llms import OpenAI
#Here we are using text-ada-001 but you can change it
llm = OpenAI(model_name="text-ada-001", n=2, best_of=2)
#Ask anything
llm("Tell me a joke")
# 输出
'\n\nWhy did the chicken cross the road?\n\nTo get to the other side.'
Prompt,我们可以提供提示模板作为输入。模板指的是我们希望获得答案的具体格式或蓝图。LangChain 提供了预先设计好的提示模板,可以用于生成不同类型任务的提示。然而,在某些情况下,预设的模板可能无法满足你的需求。在这种情况下,我们可以使用自定义的提示模板。PS:上层用户只需要输入关键词即可。
from langchain import PromptTemplate
# This template will act as a blue print for prompt
template = """
I want you to act as a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate(input_variables=["product"], template=template,)
prompt.format(product="colorful socks")
# -> I want you to act as a naming consultant for new companies.
# -> What is a good name for a company that makes colorful socks?
LLMChain ,通过链式调用的方式,把一个需要询问 AI 多轮才能解决的问题封装起来,在这个链式序列中,每个链式都有一个输入和一个输出,一个步骤的输出作为下一个步骤的输入。把一个通过自然语言多轮调用才能解决的问题,变成了一个函数调用。
chain = LLMChain(llm = llm, prompt = prompt)
想要通过大语言模型,完成一个复杂的任务,往往需要我们多次向 AI 提问,并且前面提问的答案,可能是后面问题输入的一部分。LangChain 通过将多个 LLMChain 组合成一个 SequantialChain 并顺序执行,大大简化了这类任务的开发工作。Langchain 的链式调用并不局限于使用大语言模型的接口。
- LLMMathChain 能够通过 Python 解释器变成一个计算器,让 AI 能够准确地进行数学运算。
- 通过 RequestsChain,我们可以直接调用外部 API,然后再让 AI 从返回的结果里提取我们关心的内容。
- TransformChain 能够让我们根据自己的要求对数据进行处理和转化,我们可以把 AI 返回的自然语言的结果进一步转换成结构化的数据,方便其他程序去处理。
- VectorDBQA 能够完成和 llama-index 相似的事情,只要预先做好内部数据资料的 Embedding 和索引,通过对 LLMChain 进行一次调用,我们就可以直接获取回答的结果。
- Langchain 里有 SQLDatabaseChain 可以直接让我们写需求访问数据库。 这些能力大大增强了 AI 的实用性,解决了几个之前大语言模型处理得不好的问题,包括数学计算能力、实时数据能力、和现有程序结合的能力,以及搜索属于自己的资料库的能力。你完全可以定义自己需要的 LLMChain,通过程序来完成各种任务,然后合理地组合不同类型的 LLMChain 对象,来实现连 ChatGPT 都做不到的事情。
高级功能
Memory,在 LangChain 中,链式和代理默认以无状态模式运行,即它们独立处理每个传入的查询。然而,在某些应用程序(如聊天机器人)中,保留先前的交互记录对于短期和长期都非常重要。这时就需要引入 “内存” 的概念,对整个对话的过程里我们希望记住的东西做了封装。
- 我们可以通过 BufferWindowMemory 记住过去几轮的对话,通过 SummaryMemory 概括对话的历史并记下来。也可以将两者结合,使用 BufferSummaryMemory 来维护一个对整体对话做了小结,同时又记住最近几轮对话的“记忆”。
- 可以使用 EntityMemory,它会帮助我们记住整个对话里面的“命名实体”(Entity),保留实际在对话中我们最关心的信息。
from langchain.memory import ChatMessageHistory
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0)
history = ChatMessageHistory() # 初始化 MessageHistory 对象
history.add_ai_message("你好!") # 给 MessageHistory 对象添加对话内容
history.add_user_message("中国的首都是哪里?")
ai_response = chat(history.messages) # 执行对话
print(ai_response)
Agent,某些应用可能需要不仅预定的 LLM(大型语言模型)/其他工具调用顺序,还可能需要根据用户的输入确定不确定的调用顺序。这种情况下涉及到的序列包括一个 “代理(Agent)”,该代理可以访问多种工具。根据用户的输入,代理可能决定是否调用这些工具,并确定调用时的输入。如果我们真的想要做一个能跑在生产环境上的 AI 聊天机器人,我们需要的不只一个单项技能,对于有很多个不同的“单项技能”,AI 要能够自己判断什么时候该用什么样的技能(意图识别问题)。通过“先让 AI 做个选择题”的方式,Langchain 让 AI 自动为我们选择合适的 Tool 去调用。我们可以把回答不同类型问题的 LLMChain 封装成不同的 Tool,也可以直接让 Tool 去调用特定能力的LLMChain 等工具。比如
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
from langchain.agents import AgentType
llm = OpenAI(temperature=0,max_tokens=2048) # 加载 OpenAI 模型
tools = load_tools(["serpapi"]) # 加载 serpapi 工具
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) # 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent.run("What's the date today? What great events have taken place today in history?") # 运行 agent
实战
- 完成一次问答
from langchain.llms import OpenAI llm = OpenAI(model_name="text-davinci-003",max_tokens=1024) llm("怎么评价人工智能") - 通过 Google 搜索并返回答案。 用agent
- 对超长文本进行总结。 我们通常的做法就是直接发给 api 让他总结。但是如果文本超过了 api 最大的 token 限制就会报错。这时,我们一般会进行对文章进行分段,比如通过 tiktoken 计算并分割,然后将各段发送给 api 进行总结,最后将各段的总结再进行一个全部的总结。
loader = UnstructuredFileLoader("/content/sample_data/data/lg_test.txt") # 导入文本 document = loader.load() # 将文本转成 Document 对象 text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 0) # 初始化文本分割器 split_documents = text_splitter.split_documents(document) # 切分文本 llm = OpenAI(model_name="text-davinci-003", max_tokens=1500) # 加载 llm 模型 chain = load_summarize_chain(llm, chain_type="refine", verbose=True) # 创建总结链 chain.run(split_documents[:5]) # 执行总结链,(为了快速演示,只总结前5段) - 构建本地知识库问答机器人
loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt') # 加载文件夹中的所有txt类型的文件 documents = loader.load() # 将数据转成 document 对象,每个文件会作为一个 document text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0) # 初始化加载器 split_docs = text_splitter.split_documents(documents) # 切割加载的 document embeddings = OpenAIEmbeddings() # 初始化 openai 的 embeddings 对象 docsearch = Chroma.from_documents(split_docs, embeddings) # 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询 qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(), return_source_documents=True) # 创建问答对象 result = qa({"query": "科大讯飞今年第一季度收入是多少?"}) # 进行问答 print(result)
向量数据库
chroma 是个本地的向量数据库,他提供的一个 persist_directory 来设置持久化目录进行持久化。读取时,只需要调取 from_document 方法加载即可。
from langchain.vectorstores import Chroma
# 持久化数据
docsearch = Chroma.from_documents(documents, embeddings, persist_directory="D:/vector_store")
docsearch.persist()
# 从本地目录加载数据
docsearch = Chroma(persist_directory="D:/vector_store", embedding_function=embeddings)
# 录入documents 到chroma
loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt') # 加载文件夹中的所有txt类型的文件
documents = loader.load() # 将数据转成 document 对象,每个文件会作为一个 document
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0) # 初始化加载器
split_docs = text_splitter.split_documents(documents) # 切割加载的 document
embeddings = OpenAIEmbeddings() # 初始化 openai 的 embeddings 对象
docsearch = Chroma.from_documents(split_docs, embeddings) # 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
# 创建问答对象
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(), return_source_documents=True)
# 进行问答
result = qa({"query": "科大讯飞今年第一季度收入是多少?"})
print(result)
Pinecone 是一个在线的向量数据库。所以,我可以第一步依旧是注册,然后拿到对应的 api key。
# 从远程服务加载数据
docsearch = Pinecone.from_existing_index(index_name, embeddings)
# 录入documents 持久化数据到pinecone
# 初始化 pinecone
pinecone.init(api_key="你的api key",environment="你的Environment")
loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt')
documents = loader.load() # 将数据转成 document 对象,每个文件会作为一个 document
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
split_docs = text_splitter.split_documents(documents) # 切割加载的 document
docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name) # 持久化数据到pinecone